Ever wondered why your server slows down or your app crashes unexpectedly? A reliable system monitor could be the game-changer you’ve been missing. Let’s dive into how real-time insights can transform your IT operations.
What Is a System Monitor and Why It Matters

A system monitor is a software tool designed to track, analyze, and report the performance and health of computer systems, networks, and applications in real time. It plays a crucial role in modern IT infrastructure by providing administrators with continuous visibility into system behavior, resource usage, and potential threats.

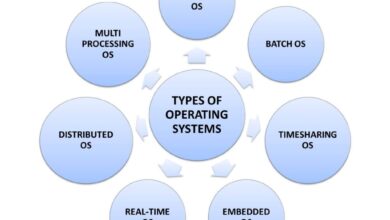
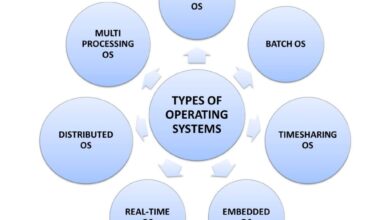
Core Functions of a System Monitor
At its heart, a system monitor performs several essential functions that keep digital environments running smoothly. These include tracking CPU usage, memory consumption, disk I/O, network activity, and process statuses. By collecting this data at regular intervals, it enables proactive maintenance and rapid response to anomalies.
- Real-time tracking of CPU, RAM, and disk usage
- Monitoring active processes and services
- Alerting on threshold breaches (e.g., high memory usage)
These functions are not just for large enterprises; even small businesses benefit from basic monitoring to prevent downtime and optimize performance.
Types of System Monitoring
There are several categories of system monitoring, each tailored to specific components of an IT environment. Infrastructure monitoring focuses on hardware and operating systems, while application performance monitoring (APM) zeroes in on software behavior. Network monitoring tracks data flow and connectivity, and log monitoring analyzes system-generated logs for errors or suspicious activity.
“Without monitoring, you’re flying blind. You won’t know when something breaks until users complain.” — DevOps Engineer, Google Cloud
Understanding these types helps organizations choose the right system monitor for their needs. For example, a web hosting company might prioritize infrastructure and network monitoring, while a SaaS provider would lean heavily on APM tools.
Top 7 System Monitor Tools in 2024
The market is flooded with system monitor solutions, but only a few stand out due to their reliability, scalability, and feature richness. Below is a curated list of the top seven tools that dominate the industry in 2024.
1. Nagios XI
Nagios XI remains one of the most trusted names in system monitoring. Known for its robust alerting system and extensive plugin ecosystem, it supports monitoring of servers, applications, services, and network protocols. Its web-based interface makes it accessible, while its open-source roots ensure flexibility.
- Supports thousands of plugins via Nagios Exchange
- Customizable dashboards and reporting
- Integrates with Slack, email, and SMS for alerts
Nagios is ideal for organizations that need deep customization and on-premise deployment. Learn more at nagios.com.
2. Zabbix
Zabbix is a powerful open-source system monitor that excels in scalability and automation. It can monitor everything from network devices to cloud environments using agents or agentless methods. With built-in AI for anomaly detection, Zabbix has evolved beyond traditional monitoring.
- Auto-discovery of network devices
- Real-time problem detection using machine learning
- Supports distributed monitoring across data centers
Zabbix is perfect for large-scale deployments where cost-efficiency and control are key. Visit zabbix.com for documentation and downloads.
3. Datadog
Datadog is a cloud-based system monitor favored by DevOps teams for its seamless integration with AWS, Azure, Kubernetes, and Docker. It provides full-stack observability, combining metrics, logs, and traces in one platform.
- Real-time dashboards with drag-and-drop widgets
- AI-powered anomaly detection and forecasting
- Extensive API for custom integrations
Datadog’s strength lies in its ecosystem. It connects with over 600 technologies, making it a top choice for dynamic, cloud-native environments. Explore it at datadoghq.com.
How a System Monitor Enhances IT Operations
Implementing a system monitor isn’t just about tracking numbers—it’s about transforming how IT teams operate. From reducing downtime to improving security, the benefits are far-reaching.
Proactive Issue Detection
One of the biggest advantages of a system monitor is its ability to detect issues before they escalate. For example, if a server’s memory usage climbs above 90%, the system can trigger an alert, allowing admins to investigate before a crash occurs.
- Threshold-based alerts prevent system overload
- Historical data helps identify recurring bottlenecks
- Automated responses can restart services or scale resources
This proactive approach reduces mean time to repair (MTTR) and improves service availability.
Performance Optimization
By analyzing trends in CPU, memory, and disk usage, a system monitor helps identify underperforming components. For instance, a database server showing high I/O wait times might benefit from SSD upgrades or query optimization.
“We reduced our server count by 30% just by identifying idle resources through our system monitor.” — CTO, TechScale Inc.
Optimization isn’t just technical—it’s financial. Eliminating waste in resource allocation leads to significant cost savings, especially in cloud environments where you pay for what you use.
Key Metrics Tracked by a System Monitor
To be effective, a system monitor must track the right metrics. These indicators provide insight into system health and user experience.
CPU and Memory Usage
CPU utilization shows how much processing power is being used. Consistently high usage (above 80%) may indicate inefficient applications or the need for hardware upgrades. Similarly, memory usage reveals how much RAM is consumed. Memory leaks in applications often show up as steadily increasing usage over time.
- Monitor per-process CPU and memory consumption
- Set alerts for sustained high usage
- Compare usage across time periods for trend analysis
Tools like htop offer command-line visibility, while enterprise monitors provide graphical dashboards.
Disk I/O and Latency
Disk input/output operations per second (IOPS) and latency are critical for database and file servers. High latency can slow down applications, even if CPU and memory are under control. A system monitor tracks read/write speeds and queue lengths to spot storage bottlenecks.
- Monitor disk queue length to detect congestion
- Track free space to prevent out-of-disk errors
- Analyze I/O patterns for optimization
For example, a sudden spike in write operations might indicate a backup job or a rogue process.
Network Throughput and Errors
Network monitoring is a core function of any system monitor. It tracks bandwidth usage, packet loss, latency, and error rates. High packet loss or jitter can degrade VoIP and video conferencing quality.
- Monitor bandwidth per interface or application
- Detect DDoS attacks through traffic spikes
- Use SNMP to gather data from routers and switches
Tools like Wireshark integrate with system monitors for deep packet inspection when needed.
Implementing a System Monitor: Best Practices
Deploying a system monitor isn’t just about installing software—it requires planning, configuration, and ongoing management.
Define Monitoring Objectives
Before choosing a tool, clarify what you want to achieve. Are you focused on uptime, security, compliance, or performance? Your goals will dictate which metrics to prioritize and which features matter most.
- Identify critical systems and applications
- Determine acceptable performance thresholds
- Align monitoring with business SLAs
For example, an e-commerce site might prioritize web server response time and database query latency during peak hours.
Start Small, Scale Gradually
Begin monitoring a few key servers or services before expanding. This approach allows you to fine-tune alerting rules and avoid alert fatigue. Once the foundation is stable, gradually add more components.
“We started with just five servers. Within three months, we scaled to 200+ with zero downtime.” — IT Manager, FinTech Solutions
Use templates and automation to streamline deployment across similar systems.
Configure Smart Alerts
Not all alerts are equal. A good system monitor lets you set intelligent thresholds and notification rules. For example, a CPU spike lasting 10 seconds might be normal, but one lasting 5 minutes warrants investigation.
- Use dynamic thresholds based on historical data
- Escalate alerts if unresolved (e.g., page after 15 minutes)
- Suppress alerts during maintenance windows
Tools like PagerDuty integrate with system monitors to manage on-call rotations and incident response.
System Monitor in Cloud and Hybrid Environments
As organizations move to the cloud, system monitoring must evolve. Traditional tools designed for on-premise servers may not fully support dynamic, ephemeral cloud resources.
Challenges in Cloud Monitoring
Cloud environments introduce complexity due to auto-scaling, containerization, and multi-tenancy. Virtual machines can appear and disappear in minutes, making persistent monitoring difficult. Additionally, cloud providers abstract hardware, limiting low-level visibility.
- Short-lived instances require agentless or API-based monitoring
- Multi-cloud setups need unified monitoring platforms
- Cost monitoring is essential to avoid billing surprises
For example, AWS CloudWatch provides native monitoring, but third-party tools like Datadog offer deeper insights across platforms.
Solutions for Hybrid Infrastructure
Many companies operate hybrid environments—part on-premise, part cloud. A modern system monitor must bridge this gap, offering consistent visibility across all environments.
- Use agents that work across OS and cloud types
- Centralize data in a single dashboard
- Apply consistent alerting policies everywhere
Tools like SolarWinds Server & Application Monitor support hybrid deployments with unified reporting and alerting.
Security and Compliance Through System Monitoring
Beyond performance, a system monitor is a vital tool for security and regulatory compliance.
Detecting Unauthorized Access
Suspicious login attempts, unusual process activity, or unexpected configuration changes can signal a security breach. A system monitor can detect these anomalies and trigger immediate alerts.
- Monitor failed SSH or RDP login attempts
- Track changes to critical system files
- Alert on processes running under unusual user accounts
Integration with SIEM (Security Information and Event Management) systems enhances threat detection.
Meeting Compliance Requirements
Industries like healthcare and finance must comply with regulations such as HIPAA, GDPR, or PCI-DSS. These often require logging and monitoring of system access and changes.
“Our system monitor provided the audit trail needed for our PCI audit—saved us weeks of manual work.” — Security Officer, PayGate Inc.
Features like log retention, user activity tracking, and report generation help meet compliance mandates efficiently.
Future Trends in System Monitoring
The field of system monitoring is rapidly evolving, driven by AI, automation, and changing IT architectures.
AI-Powered Anomaly Detection
Traditional threshold-based alerts are being replaced by AI models that learn normal behavior and flag deviations. This reduces false positives and detects subtle issues humans might miss.
- Machine learning identifies baseline performance
- Auto-correlates events across systems
- Predicts failures before they occur
For example, Google’s SRE team uses AI to predict disk failures based on SMART data trends.
Observability Over Monitoring
The industry is shifting from monitoring to observability—a broader concept that includes metrics, logs, and traces. Observability tools allow engineers to ask arbitrary questions about system behavior, rather than relying on pre-defined alerts.
- Three pillars: metrics, logs, traces
- Enables root cause analysis in complex microservices
- Tools like Prometheus, Grafana, and OpenTelemetry lead this shift
This trend is especially relevant for cloud-native applications using Kubernetes and serverless architectures.
What is a system monitor used for?
A system monitor is used to track the performance, availability, and health of IT systems. It helps detect issues like high CPU usage, memory leaks, network bottlenecks, and security threats in real time, enabling quick response and minimizing downtime.
Which system monitor tool is best for beginners?
For beginners, tools like Zabbix or PRTG Network Monitor offer user-friendly interfaces and guided setup processes. They provide essential monitoring features without requiring deep technical knowledge, making them ideal for small teams or learning environments.
Can a system monitor prevent server crashes?
While a system monitor can’t prevent crashes directly, it enables proactive intervention by alerting administrators to warning signs like high resource usage or failing hardware. This early detection allows corrective actions before a crash occurs.
Is system monitoring necessary for cloud environments?
Yes, system monitoring is crucial in cloud environments due to their dynamic nature. Auto-scaling, ephemeral containers, and distributed services require continuous visibility to ensure performance, security, and cost control.
How does AI improve system monitoring?
AI improves system monitoring by learning normal behavior patterns and detecting anomalies without predefined thresholds. It reduces false alerts, identifies complex issues faster, and can even predict failures based on historical trends, enhancing overall system reliability.
In today’s fast-paced digital world, a robust system monitor is no longer optional—it’s essential. From preventing downtime to ensuring security and compliance, the right tool provides invaluable insights. Whether you’re managing a single server or a global cloud infrastructure, investing in effective monitoring pays off in reliability, performance, and peace of mind. As technology evolves, so too must our approach, embracing AI, observability, and automation to stay ahead of the curve.
Further Reading: